Seit mehr als 25 Jahren ist das Internet Protocol (IP) Version 4 im Einsatz. Dieses Protokoll wurde für kleinere Netzwerke geschrieben und kommt langsam an die Grenzen seiner Möglichkeiten. Die neue Generation dieses Protokolls ist die Version 6 und wird IPv6 oder IPng (Next Generation) genannt. Diese neue Version ist schon seit geraumer Zeit einsatzbereit, wird jedoch noch nicht sehr häufig eingesetzt.
Die auffallendste Neuerung betrifft die Adressgrösse. Bei IPv4 ist der zur Verfügung stehende Adressraum 32 Bit, bei IPv6 beträgt er 128 Bit. Dies entspricht ca. 1035 möglichen Adressen. Daneben gibt es eine Reihe anderer Vorteile gegenüber dem alten IP. So kann ein IP-Paket auf seinem Weg nicht mehr fragmentiert werden, was bedeutet, dass jede Fragmentationsinformation aus dem Header gestrichen wurde. Jedes Netzwerkinterface kann zudem mehrere IP-Adressen zugewiesen bekommen. Da auch Applikationen (ab Layer 5) mit IP-Adressen arbeiten, müssen diese auch dem neuen Internet Protocol angepasst werden.
| Eigenschaften | IPv4 | IPv6 |
| Adressbreite | 32 Bit | 128 Bit |
| Anzahl Adressen pro NIC | 1 | beliebig |
| Fragmentieren | alle Router | nur Sender |
| Autokonfiguration | nein | ja |
| Headergrösse | 40 Byte (fix) |
Die Adressierung ist im RFC 2373 (6) spezifiziert. Die Übernahme der alten Adressschreibweise hätte bei IPv6 unweigerlich zu sehr langen Zahlenkolonnen geführt. Aus diesem Grund wurde eine kompaktere Schreibweise gewählt, die anhand eines Beispiels erläutert werden soll:
Eine besondere Adresse ist die Loopbackadresse (äquivalent zu 127.0.01 bei IPv4) 0:0:0:0:0:0:0:1 oder kurz ::1. Die Adresse 0:0:0:0:0:0:0:0 oder :: ist nicht definiert und darf nicht benützt werden.
IPv6-Adressen werden unterteilt in Adressen mit und Adressen ohne Präfix. Die Adressen mit Präfix haben einen sogenannten Netzwerkteil. Um die Grösse des Netzwerkteils anzugeben, werden die Anzahl Einsen der Netzadresse in Binär-Schreibweise gezählt und diese Zahl einfach mit einem Schrägstrich hinter die IP-Adresse gehängt (z. B. 2030:F5C4:12:5A43::/64).
Es existiert eine Reihe von definierten Adresstypen, welche anhand der ersten Bytes erkennbar sind:
| Erste Bytes einer Adresse in Hex | Bedeutung |
| 02 bis 03 | reserviert für NSAP-Adressen |
| 04 bis 05 | reserviert für IPX-Adressen |
| 20 bis 3F | aggregierbare globale Unicast-Adressen |
| FE 80 bis FE BF | link-local Unicast-Adressen |
| FE C0 bis FE FF | site-local Unicast-Adressen |
| FF | Multicast-Adressen |
Alle anderen Adressen sind nicht zugewiesen. Daneben gibt es noch Sonderadressen, die für die Übergangszeit gültig sind. Diese Adressen sind auch im RFC 2373 (6) beschrieben.
Zur Zeit laufen in der IETF Bestrebungen, die heutigen Site-Local-Adressen durch ein ausgefeilteres Konzept zu ersetzen (vgl. (13)), da es sich gezeigt hat, dass die Site-Local-Adressen für Entwickler und Netzwerkbetreuer ähnliche Probleme bereiten wie die lokalen IPv4-Adressen (192.168.0.0/16, 10.0.00/8 etc.), nämlich die fehlende Gewährleistung der weltweiten Eindeutigkeit und die damit verbundenen Unannehmlichkeiten. Ausserdem wird bemängelt, dass das Konzept einer Site zu wenig durchdacht und zu unflexibel für die realen Bedürfnisse der Nutzer ist.
Die manuelle Adressvergabe ist nur für sehr kleine Netzwerke zu empfehlen. Der Verwaltungsaufwand, jedem einzelnen Host von Hand eine Adresse zu vergeben, ist heutzutage nicht mehr vertretbar. Zudem besteht die Gefahr, dass zwei Hosts dieselbe Adresse erhalten.
Gegenüber IPv4 ist die Version 6 dieses Protokolls in der Lage, automatisch IP-Adressen zu vergeben. Bei dieser Autokonfiguration (RFC 2462 (21)) wird eine verbindungslokale Netzadresse (link local) generiert. Der Adresspräfix lautet darum FE:80 bis FE:BF. Die Interface-ID der Adresse ist abhängig von der benutzten Link-Layer-Technologie. Beim Ethernet wird die 48-Bit lange MAC-Adresse nach einer festen Regel in die Interface-ID (EUI-64) umgewandelt (RFC 2464 (4)).
Zusätzlich kann auch eine global gültige Adresse bestimmt werden, wenn im Netz ein Router vorhanden ist, der Router Discovery gemäss RFC 2461 (17) unterstützt. Ein solcher Router versendet periodisch sogenannte Router Advertisements - Multicast-Nachrichten, welche den im lokalen Netz zu benutzenden Präfix bekannt machen.
Die Hosts im Netz bestimmen dann aus diesem Präfix und der EUI-64 eine IPv6-Adresse und können so ohne manuellen Eingriff oder irgendwelche zusätzlichen Server Zugriff aufs Netz erhalten.
Zur Vermeidung von doppelten Adressen schickt der Knoten eine spezielle Nachbaranfrage, die als Zieladresse die zu überprüfende Adresse und als Absenderadresse 0::0 enthält. Diese Absenderadresse kennzeichnet die Nachricht als Duplicate Address Detection-Nachricht. Wird dadurch ein Adresskonflikt festgestellt, so wird die betroffene Adresse überhaupt nicht mehr verwendet.
Der DHCP-Dienst existiert trotz Autokonfiguration unter IPv6 weiter. Dieser Dienst, DHCPv6 genannt, hat unter anderem die Aufgaben, IP-Adressen dynamisch zu vergeben und andere IP-Parameter zu konfigurieren. Im Zusammenspiel mit dem DNS-Server kann somit eine bequeme Verwaltung der IP-Adressen und deren Namen erreicht werden.
Stateful wird diese Art der Autokonfiguration deshalb genannt, weil der DHCP-Server im Gegensatz zum Advertising Router bei der Stateless Autoconfiguration über den Zustand seiner Clients informiert ist und damit einem Netzwerkoperator bessere Kontrolle über die zugelassenen Hosts in seinem Netz gibt.
Ein Netz ohne DHCP-Server ist mit IPv6 ein Sicherheitsrisiko, da sich ein fremder Host ohne Probleme mittels Autokonfiguration eine IP-Adresse beschaffen kann. Wo dies kein Problem darstellt (z. B. in komplett öffentlichen oder in physisch gesicherten Netzen) kann DHCPv6 auch bloss als Ergänzung zur Stateless Autoconfiguration dienen.
DCHPv6 hat erst im Juli 2003 den Status eines RFCs erreicht (RFC 3315 (8)). Auf dem Markt gibt es darum noch keine fertigen Implementationen von DHCPv6-Servern für Linux. Aus diesem Grund wurden die Versuche nur mit Stateless Autokonfiguration durchgeführt.
IPv6 befindet sich derzeit in der Testphase. Darum wurde ein Backbone mit IPv6 realisiert. Dieses Netz nennt sich 6Bone und wird vor allem von Universitäten und Telekommunikationsfirmen getragen. Das Ziel dieses Netzwerks ist das Testen der Standards und vermehrt auch des operationellen Betriebs. In der Schweiz gibt es zur Zeit zwei ISPs, die den Zugang via IPv6 anbieten.
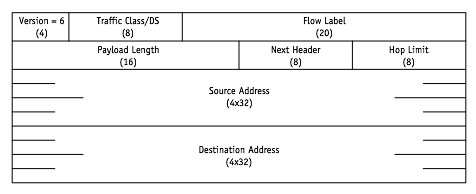
Verglichen mit dem IPv4-Header ist der IPv6-Header relativ einfach aufgebaut. Wegen der 128 Bit langen Adressen ist er jedoch doppelt so lang (40 Byte) wie der minimale Header des alten Protokolls.
| Version | Internet Protocol Version, muss 6 sein. |
| Traffic Class | Dieses Feld ist für ideales Routing vorgesehen. Je nach Anforderung kann das Paket auf dem besten Weg zum Ziel geführt werden. Hat die gleiche Bedeutung wie das Type of Service Feld im IPv4-Header. |
| Flow Label | Kann von einem Host benutzt werden, um einzelnen Paketen eine Sequenznummer zu geben. Dieses Feld ist immer noch experimentell. |
| Payload Length | Länge der Daten nach dem Header. Erweiterungs-Header werden auch als Daten angesehen. |
| Next Header | Beschreibt die Art des nächsten Headers. |
| Hop Limit | Maximale Anzahl von Knoten, die ein Paket durchlaufen darf. |
| Source Address | Adresse des Senders. |
| Destination Address | Adresse des Empfängers. |
Um den Header eines IPv6-Paketes kleiner zu machen, wurden die Optionsfelder weggelassen. Diese Funktionen werden neu mit Erweiterungs-Header realisiert. Die einzelnen Erweiterungs-Header sind im RFC 2460 (7) definiert.
Der Typ jedes Erweiterungs-Headers wird jeweils im Next-Header-Feld des vorangegangenen Headers festgelegt. Damit ist es möglich, eine beliebige Anzahl von Erweiterungsheadern in einem IPv6-Paket zu transportieren, denn jeder Erweiterungsheader besitzt als erstes ein 8-Bit-Feld Next Header. Der letze Erweiterungs-Header in jedem Paket enthält im Next-Header-Feld den Payload-Typ (z. B. 0x06 bei TCP).
Der Vorteil dieser Methode ist, dass der IPv6-Header in der Struktur sehr einfach gehalten werden kann und neue Optionen flexibel durch neue Extension-Header definiert werden können. Ausserdem vereinfacht sich IP-over-IP-Tunneling, da bereits durch Anfügen eines IPv6-Headers mit Next Header = IPv6 im Prinzip ein Tunnel geschaffen wird. Auch dieser übergeordnete IPv6-Header kann wieder Erweiterungs-Header besitzen.
Von Fragmentierung wird in IPv6 abgeraten, obwohl es über entsprechende Erweiterungs-Header weiterhin möglich ist. Da allerdings IPv6 eine MTU von 1280 Bytes oder mehr voraussetzt (RFC 2460 (7)) und generell Path MTU Discovery (vgl. Kapitel 2.5) zur Bestimmung der MTU zwischen zwei Endknoten benutzt wird, ist Fragmentierung in der Regel nicht notwendig, es sei denn, das höhere Protokoll unterstützt nur Paketgrössen, die die MTU übersteigen. In diesem Fall geschieht die Fragmentierung ausschliesslich am sendenden Endknoten und nicht wie unter Umständen bei IPv4 auf dem Weg.
Path MTU Discovery ist ein Verfahren, um die MTU für einen bestimmten Pfad in einem Netzwerk zu bestimmen. Für IPv6 ist es im RFC 1981 (15) spezifiziert. Die Idee ist, dass ein Knoten grosse Datenpakete stets in grösstmögliche IP-Pakete verpackt, um so den Protokoll-Overhead möglichst gering zu halten und die verfügbare Bandbreite optimal auszunutzen.
Ein Knoten geht zunächst davon aus, dass die Path MTU (PMTU) eines bestimmten Pfades der MTU des ersten Links entspricht und benutzt diese als Maximalgrösse für die IP-Pakete. Ist ein solches Paket für einen Link im Pfad zu gross, wird es vom zuständigen Knoten verworfen und eine Packet Too Big ICMPv6-Meldung an den sendenden Knoten geschickt. Diese Meldung enthält die MTU des Links, der sendende Knoten nimmt nun diese MTU als neue PMTU für den Pfad an. Dieser Vorgang kann sich mehrmals wiederholen, wenn weitere Links im Pfad eine noch kleinere MTU besitzen.
Da sich die PMTU durch Änderungen im Routing im Verlauf der Zeit ändern kann, wird der sendende Knoten periodisch versuchen, die PMTU wieder hinaufzusetzen, um nicht unnötig kleine Pakete zu versenden. Verkleinert sich die PMTU während der Übertragung, so wird dies über die entsprechenden Packet Too Big-Meldungen automatisch erkannt.
Path MTU Discovery ist nicht zwingender Bestandteil von IPv6-Implementationen. Knoten, die Path MTU Discovery nicht unterstützen, benutzen als MTU die minimale Paketgrösse von IPv6 wie sie im RFC 2460 (7) festgelegt ist, also 1280 Bytes. Dies ist besonders für Geräte mit minimalem IPv6-Stack (z. B. Boot-ROMs, embedded Devices) vorgesehen.
Um eine sanfte Umstellung von IP-Netzen von Version 4 zu Version 6 zu ermöglichen, wurden verschiedene Transition Mechanisms vorgesehen. Die wichtigsten sind:
Diese Mechanismen sollen es ermöglichen, ein Netz schrittweise auf IPv6 zu migrieren, ohne die Funktionalität während der Umstellung zu beeinträchtigen. Es ist dadurch sogar möglich (und üblich), die Umstellung über Jahre hinzuziehen.
Im Dual-Stack-Betrieb besitzt jeder Knoten Unterstützung sowohl für IPv4 als auch für IPv6. Je nach Bedarf läuft dann die Kommunikation über den einen oder den anderen Protokollstack. Nicht nur das Betriebssystem sondern auch die einzelnen Anwendungen müssen beide Protokolle unterstützen.
Alle wichtigen modernen Desktop-Betriebssysteme unterstützen mittlerweile den Dual-Stack-Betrieb, bei den Anwendungen hinkt die Entwicklung noch etwas hinterher.
Diese Übergangsstrategie ist vor allem im Server-Bereich enorm wichtig, damit sowohl IPv4- als auch IPv6-Clients auf die angebotenen Dienste zugreifen können.
Durch Tunneling können reine IPv6-Netze über ein reines IPv4-Netz miteinander verbunden werden. Die jeweiligen Router zwischen dem IPv6- und dem IPv4-Netz stellen die Endpunkte des Tunnels dar und packen die IPv6-Pakete in IPv4-Pakete ein und aus. Das Tunneling ist für die IPv6-Knoten völlig transparent.
Innerhalb des Tunnels können alle IPv6-Erweiterungen wie Verschlüsselung und Authentifizierung ohne Einschränkungen benutzt werden, es ist also auch ein Peer-to-Peer-VPN-Betrieb zwischen einzelnen IPv6-Knoten aus verschiedenen Netzen möglich.
Network Address Translation - Protocol Translation (kurz NAT-PT) ist ein weiterer Mechanismus, der während einer Umstellung eines Netzes auf IPv6 zum Einsatz kommt. Im Gegensatz zu den anderen Mechanismen muss nur der Router (der NAT-PT Gateway) NAT-PT unterstützen. Die Endpunkte können reine IPv4- beziehungsweise IPv6-Hosts sein.
Der Nachteil an NAT-PT ist, dass der NAT-PT-Gateway Application Level Gateways (ALG) anbieten muss für Protokolle, welche IP-Adressen im Paketinhalt mitführen. Der offensichtlichste Fall ist das DNS-Protokoll, aber beispielsweise auch FTP benötigt einen ALG um über NAT-PT zu funktionieren.
Der typische Anwendungsfall von NAT-PT dürfte also sein, in einem reinen IPv6-Netz Dienste anzubieten, für die ausschliesslich eine IPv4-Implementation existiert.
Der NAT-PT-Gateway ist ein Router, der IPv4-Pakete in IPv6-Pakete umwandelt und umgekehrt. Bei der Umsetzung der IP-Pakete werden einige Header übernommen, andere werden auf Standardwerte gesetzt und wieder andere komplett verworfen:
| IPv6-Header | Umsetzung | IPv4-Header |
| Version = 6 | überschreiben | Version = 4 |
| Traffic class | kopieren | Type of Service |
| Flow label | auf 0 setzen | -- |
| Payload length | umrechnen | Total length |
| Next header | kopieren | Protocol |
| Hop limit | kopieren | TTL |
Es existieren drei grundsätzlich unterschiedliche NAT-PT-Methoden:
Für eine detaillierte Beschreibung sei auf RFC 2766 (23) verwiesen, in welchem das Verfahren anhand einfacher Beispiele erläutert wird.
Wie NAT-PT ermöglicht es auch TRT einem IPv6-Only-Netz, transparent auf das IPv4-Internet zuzugreifen. Der umgekehrte Weg ist allerdings nicht vorgesehen. Die Funktionsweise von TRT ist auf den ersten Blick ähnlich wie die des dynamischen NAT-PT. Es kommt ebenfalls ein DNS-ALG zum Einsatz und DNS-Requests und -Responses werden von diesem genauso bearbeitet wie bei NAT-PT.
Die eigentliche Verbindung zum Zielhost wird über den TRT-Server abgewickelt. Im Unterschied zu NAT-PT und herkömmlichem NAT wird nicht die Verbindung direkt umgesetzt und weitergereicht, der TRT-Server agiert vielmehr als Endpunkt der eingehenden IPv6-Verbindung und baut nach aussen selbständig eine IPv4-Verbindung auf. Dieser Unterschied mag unbedeutend scheinen, bietet aber einen offensichtlichen Vorteil: Verbindungsabbrüche werden in jedem Fall korrekt erkannt, da die jeweiligen Endpunkte in direktem Kontakt stehen und ICMP-Meldungen korrekt gesendet und empfangen werden.
TRT ist für die Endsysteme komplett transparent, es ist keinerlei Anpassung an Clients oder Anwendersoftware notwendig. Für den Betrieb wird nur eine einzelne IPv4-Adresse für den TRT-Server benötigt. Ein Nachteil ist, dass TRT wie NAT-PT für spezielle Protokolle Application Level Gateways benötigt.
Für die Implementation eines TRT-Servers unter Linux ist ein deutschsprachiges How-To verfügbar (TRT-Howto (19)), in dem auch das Funktionsprinzip ausführlich erklärt wird.